Natality Data Analysis
Check out the Natality Analysis site here!
For the past few months, I've been working on my first real data analysis project. I've been studying data science for the past year, and now that I'm nearing graduation, I'm applying the concepts from each class into one big project.
Project Overview
This is a living project, and I'm actively adding new parts as I learn new things. However, at the time of writing, the project is made up of the following:
- An overview of the entire dataset
- A binary classifier to predict the likelihood of a successful vaginal birth after c-section (VBAC)
I am currently working on an analysis of Down syndrome factors.
About the Dataset
While I've been studying, I've been paying my bills by working at an OB/GYN clinic. After being surrounded by women in various stages of pregnancy, I became interested in studying the topic of pregnancy and birth outcomes.
After reading a few academic papers about pregnancy statistics, I chose to work with the 2021 Natality dataset from the CDC (which you can find here).
Data Preparation
The dataset is encoded in fixed width format, so my first step was to translate that into a format I could read into a dataframe. I spent a few hours combing through the reference packet to enter the widths in by hand.
Then, because the resulting dataframe was so large (about 225 features and 3 million+ rows), I saved it out as a parquet file.
Data Cleaning
My first priority to clean up the dataset was to remove any unimportant columns. Many of the features had "reporting" and "data imputed" flags, which are important for data integrity, but wouldn't be helpful in training machine learning models. In my first cleaning pass, I removed those columns, leaving me with closer to 150 columns. much more manageable!
I chose not to go through each column to clean up nulls. I knew I would not be likely to need all those columns for any models I trained, so I opted for a "clean as I go" approach.
When it came to working on the VBAC data specifically, I used a random forest to determine feature importances (more on that later) and cleaned those features before model selection.
Feature Selection
Faced with over 150 potential features to feed into my models, I started narrowing down my feature selection by eliminating features that were unrelated to labor, such as features recorded after the birth (for example, anything related to the newborn's care post-birth).
I then fed the dataset into a random forest classifier so I could use its feature_importances_ data to inform which features to focus on.
Visualization
To visualize an overview of the entire dataset, I created charts to visualize a subset of the features, focusing on a few areas: parental demographics, maternal characteristics, characteristics of labor, and pregnancy outcomes.
For the VBAC predictor, I narrowed in on mothers who had had a previous c-section. Like with the dataset overview visualizations, I selected a subset of the available features, focusing mainly on characteristics of labor.
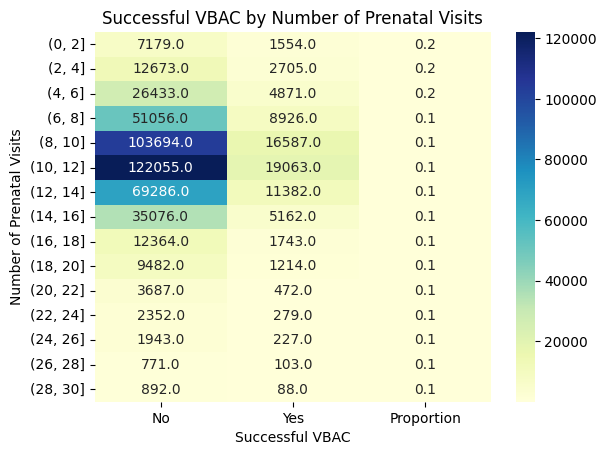
I was surprised to find that some assumptions I'd made about the data were proven incorrect by the visualizations. For example, I had read in a study that mothers with little to no prenatal care were more likely to have a c-section. The study identified a few possible reasons, including lack of communication with the birth attendant, or lack of a detailed birth plan. However, when I examined number of prenatal visits compared to rate of successful VBAC, I found that the opposite was true.
Model Selection
With the insights gained from my visualizations, I chose to train three models: a logistic regression model, a random forest classfier, and a neural network.
In the end, they all performed about the same, with each achieving an F1 score of about 0.57. I found that each model had a high false positive rate.
I initially selected the neural network as my final model, as it performed slightly better than the other models, but I found that I was unable to use TensorFlow on my backend service provider due to size constraints. My random forest was within those constraints, so that was the model I ended up deploying.
Model Deployment and User Interface
I built a user interface using React and NextJS, and connected that to my Flask backend. This was my first time using Flask, and there was a bit of a learning curve, but I was able to build what I needed without much trouble.
Challenges
The most difficult part of this project was definitely the size of the dataset. Before I learned about using a random forest for feature selection, I spent a long time selecting features based on domain knowledge, but that was time-consuming and flawed due to my limited understanding of pregnancy (because I'm not a doctor).
One thing I learned was the importance of using visualizations to inform feature selection. Initially, I launched a model with 13 features, but I found its output to be confusing at times, which indicated to me that I had made some incorrect choices in my feature selection. I decided to backtrack and spend more time on visualization, and I found that I had chosen some features that didn't make sense or were negatively correlated with a successful VBAC. Once I removed those features, I found the output to be much more logical.
One thing I would like to change about this project in the future is learning to deploy a neural network. I'm sure it can be done, but I'll need to do more research into my backend service provider to learn how.
Conclusion
Overall, I'm proud of the results of this project, and I'm excited to continue diving into the data!